Copying Large Datasets to Your Object Storage Bucket with the AWS Command Line Interface


The beauty of having your data in your object storage (S3 bucket) is that any machine or projects you create in RONIN can access the data.. only if you want it to.
If you're a Windows or Mac user, you can read this article on copying data to an object store via Cyberduck. However for large data sets, we recommend using the Amazon Command Line Interface (CLI).
I have an Object Store already, lets get started!
Step 1 - Download and Setup the Amazon Command Line Interface (CLI) on the machine where your data is stored.
Amazon provide a wonderful article on installing the CLI here
If you're not sure whether you have already, run in a terminal
which awsand if nothing is returned, you need to install.
Step 2 - Open your key file for configuration
You will need to open your downloaded csv file that was created when you made the object store (eg. bucket.store.ronin.cloud.csv)
Step 3 - Configure the CLI to use your newly generated key
Run the following command in your terminal window, and enter the following prompts.
aws configureAWS Access Key ID - Located in your downloaded key file
AWS Secret Access Key - Located in your downloaded key file
Default region name - Located on the object store info page in RONIN
Default output format - JSON
Step 4 - Copy your files to your object store!
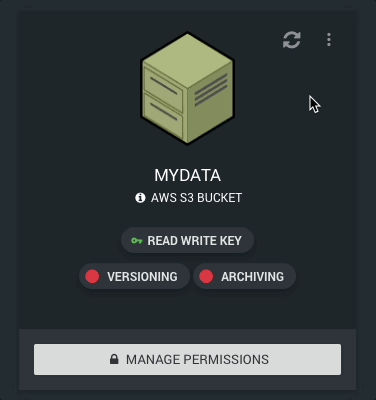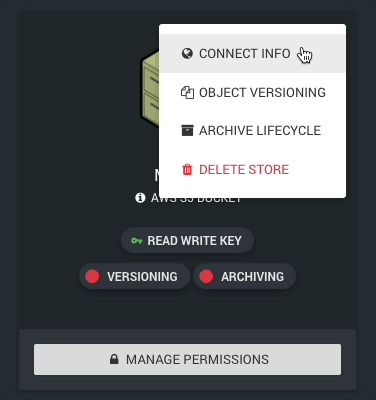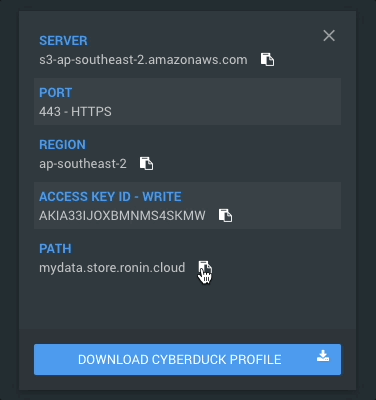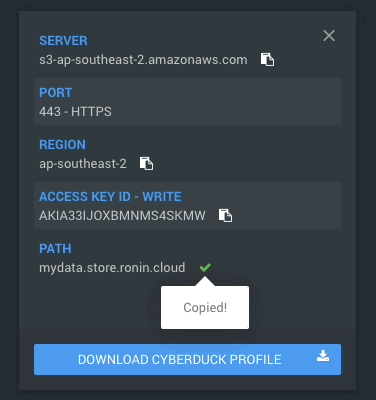
Navigate to where you data is stored on the machine in a terminal. Use the following code to sync your data across to the object store, replacing "bucket.store.ronin.cloud" with the path to your respective object store. Here's how you can find the path of your object store from the Object Storage screen in RONIN:
aws s3 sync . s3://bucket.store.ronin.cloudNote: To potentially improve performance, you can modify the value of max_concurrent_requests. This value sets the number of requests that can be sent to Amazon S3 at a time. The default value is 10, and you can increase it to a higher value. However, note the following:
-
Running more threads consumes more resources on your machine. You must be sure that your machine has enough resources to support the maximum number of concurrent requests that you want.
-
Too many concurrent requests can overwhelm a system, which might cause connection timeouts or slow the responsiveness of the system. To avoid timeout issues from the AWS CLI, you can try setting the --cli-read-timeout value or the --cli-connect-timeout value to 0.
For more info visit https://aws.amazon.com/premiumsupport/knowledge-center/s3-improve-transfer-sync-command/
Your data should now be available in the object store. To confirm, use the following prompt (again replacing 'bucket.store.ronin.cloud' with your object store path):
aws s3 ls s3://bucket.store.ronin.cloudWell done, your data is now in your Object Store and ready to be accessed by any machine or clusters you create in RONIN!
